Getting answers and having meaningful discussions for questions that require human expertise and opinions can be difficult. Online forums provide a medium to facilitate this type of interaction, but the vast amount of online forums can make it difficult to find the right place to post a question or look for answers. This tool addresses the problem by finding the most relevant forum for a given question. The model is developed by creating a dataset of forum posts and fine-tuning a transformer based model with the dataset.
The dataset is created from 148k forum posts from StackExchange, an online discussion board meant strictly for questions and answers. The dataset samples 1k posts across 148 forums from
StackExchange data dumps released at the end of October 2022. The dataset can be found on
HuggingFace.
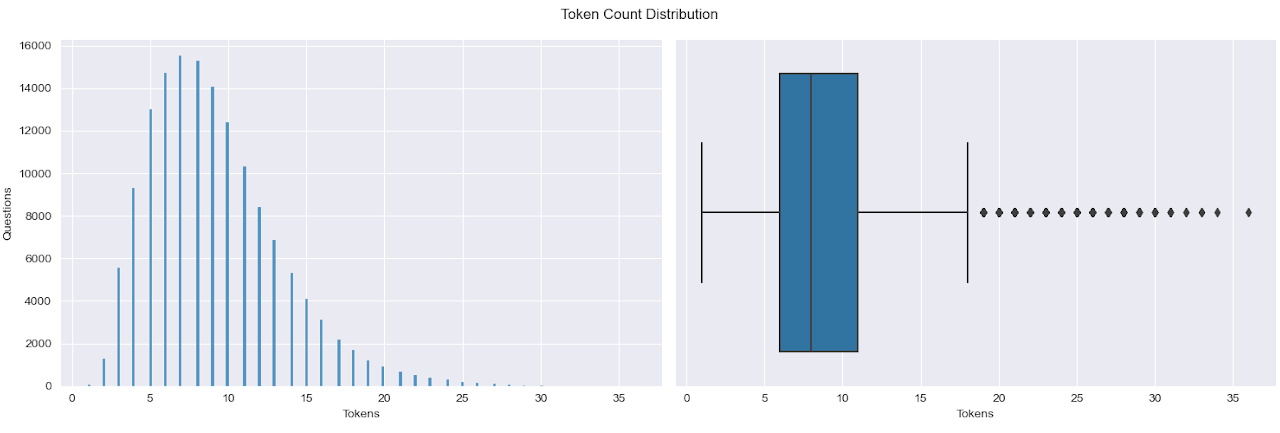
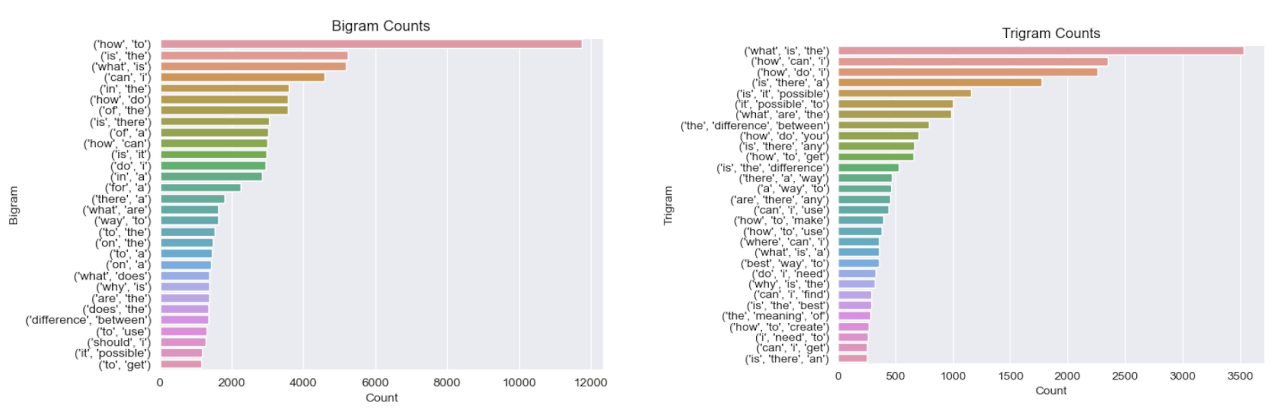
Post titles (generally the question being asked or a summary of the question) are used as the input text for training the model. The dataset contains post titles with a wide range of sizes and syntaxes.
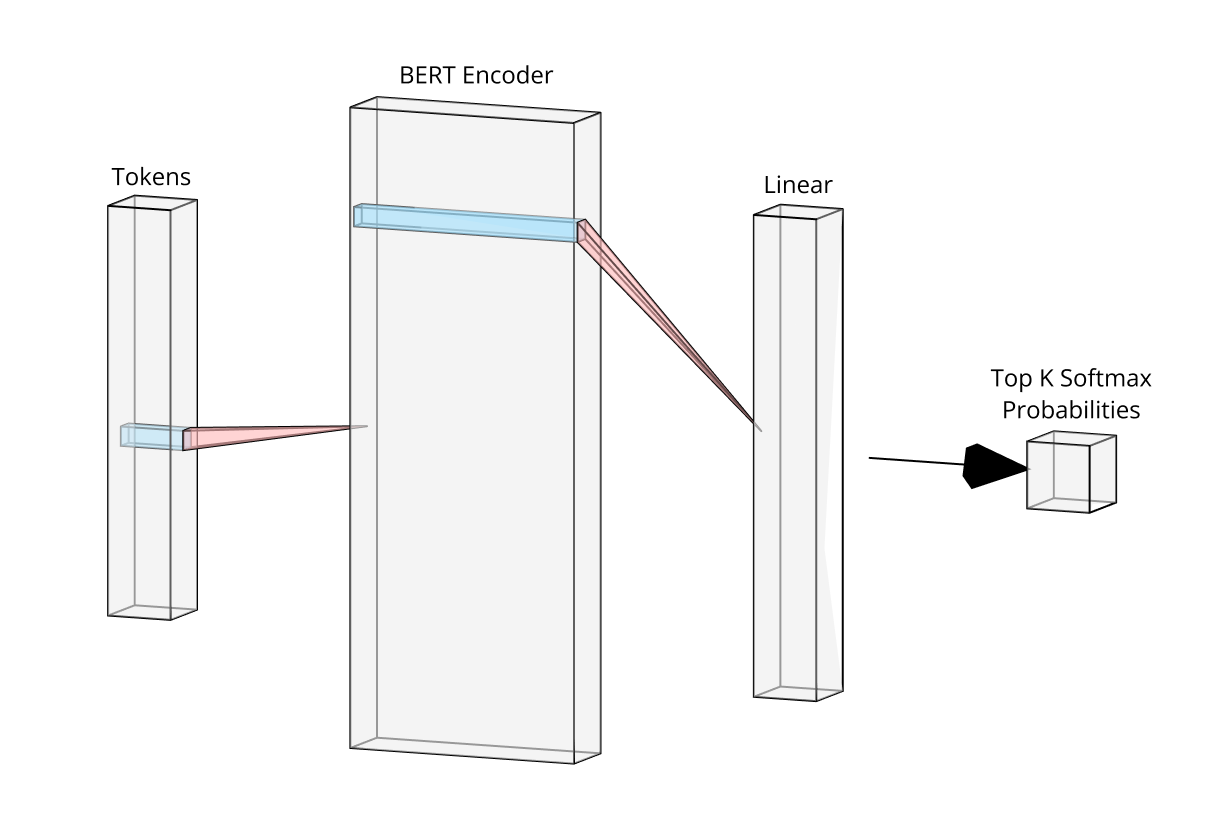
The model fine tunes the pre-trained BERT model with an additional classification layer. It takes in text as input and outputs the probability of the text belonging to each of the 148 classes.
-
The input text is tokenized, converting words into token IDs and creating attention masks.
-
The tokenized text is passed through a BERT encoder, which consists of 12 transformer layers with 12 attention heads and a hidden size of 768.
-
The encoder output is passed through a dropout layer with a rate of 0.5, randomly deactivating 50% of the neurons to prevent overfitting.
-
The dropout output is passed through a linear layer that reduces the dimensionality of the embedding to 148, which represents the number of target classes for multi-class classification.
-
The output of the linear layer is passed through a softmax function to convert the values into 148 class probabilities.
The model was implemented in PyTorch and can be found on
HuggingFace.
The model was trained by passing in the title ofthe forum post and optimizing the model to predict the correct forum that the post belongs to.
-
Criterion: Cross Entropy Loss
-
Optimizer: Adam
-
Learning Rate: 1-6
-
Batch Size: 2
-
Epochs: 30
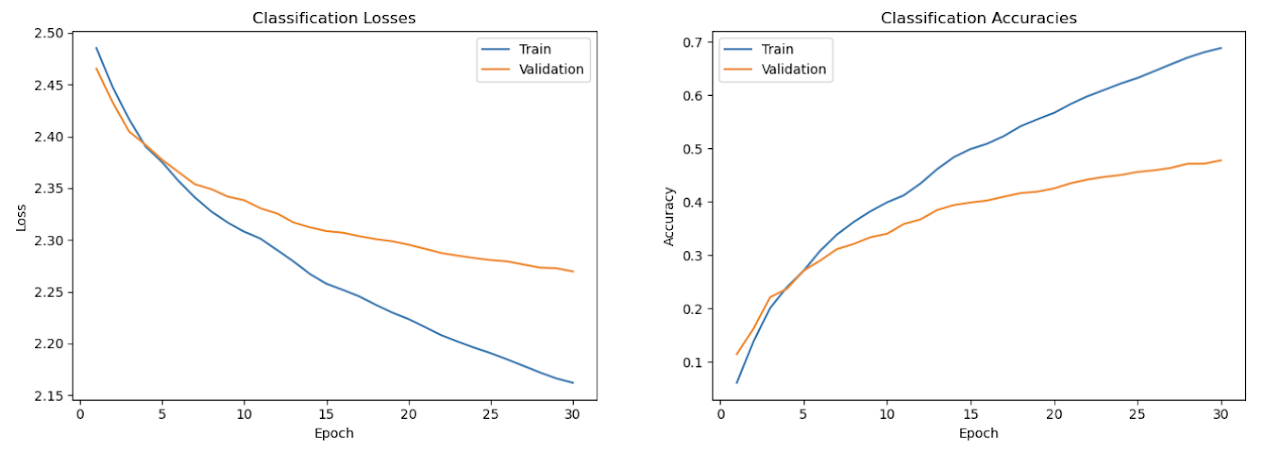
After training, the model achieved a test accuracy of 48%, which is a solid result given that there are a large number of classes with overlapping topics. The model has good empirical results and can be run by setting up the codebase found on
GitHub.